
서비스를 제공하는 웹사이트에서 페이징 알고리즘을 쓰지 않는 곳은 없을 것이다.
페이징 알고리즘을 어떤 방법을 적용하느냐에 따라서 엄청난 성능 차이가 있을 수 있다.
예를 들어 아래와 같은 데이터가 있다고 가정해보자.
SELECT COUNT(*) FROM dbo.TBLINSA_SH_FINAL WITH(NOLOCK)
SELECT * FROM dbo.TBLINSA_SH_FINAL WITH(NOLOCK)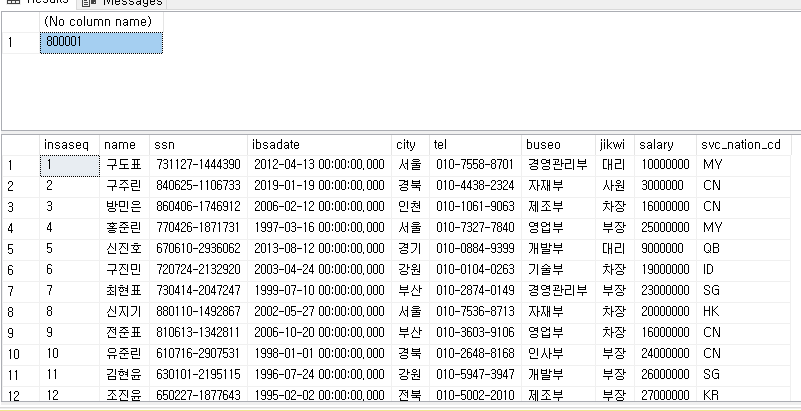
테이블 스키마와 인덱스 구성은 아래와 같다.
페이징 처리에서 정렬 자체를 salary와 ibsaDate로 할 것이기 때문에 아래와 같이
non-clustered index를 구성하였다.
clustered index는 insaseq로 고유번호를 지정해두었다.

declare @page_num int -- 페이지 번호
, @per_page_row int -- 페이지 별 로우수
set @page_num = 2000
set @per_page_row = 10
SELECT TOP (@per_page_row) *
FROM (
SELECT TOP (@page_num * @per_page_row) *
, ROW_NUMBER() OVER (ORDER BY salary DESC, ibsadate DESC) AS rnum
FROM dbo.TBLINSA_SH_FINAL WITH(NOLOCK)
ORDER BY salary DESC, ibsadate DESC
) a
WHERE a.rnum >= (@page_num - 1) * @per_page_row + 1
위와 같이 쿼리를 짜게 되면 TBLINSA_SH_FINAL 테이블에서
한 페이지당 10장씩 묶음으로 총 2000장을 넘긴 후의 페이지이다.
실행계획은 아래와 같다.


위와 같은 식으로 읽게 되면 아래처럼 LOOK UP을 2만 번이나 수행하게 되어
I/O 읽기가 많이 발생하는 것을 볼 수 있다.

페이징 처리를 아래와 같이 offset-fetch 구문을 사용해서 이용하면 가독성은 높아지나
실행계획은 위의 방식과 같아서 성능적으로 좋아지는 부분을 찾을 수는 없다.
declare @page_num int -- 페이지 번호
, @per_page_row int -- 페이지 별 로우수
set @page_num = 2000
set @per_page_row = 10
SELECT *
FROM dbo.TBLINSA_SH_FINAL WITH(NOLOCK)
ORDER BY salary DESC , ibsadate DESC
OFFSET (@PAGE_NUM - 1) * @PER_PAGE_ROW ROWS
FETCH NEXT (@PER_PAGE_ROW) ROWS ONLY
애초에 모든 데이터를 읽고 20000개를 넘어 뛰고 읽는 것은 방대한 KEY LOOKUP을 야기한다.
아래와 같이 부분 범위만 읽어와서 CLUSTERED INDEX를 통해 데이터에 빠르게 접근해주는 방법은
KEY LOOKUP 자체를 없애주는 효과를 발휘한다.

위와 같은 알고리즘을 적용한 쿼리는 아래와 같이 표현할 수 있다.
declare @page_num int -- 페이지 번호
, @per_page_row int -- 페이지 별 로우수
set @page_num = 2000
set @per_page_row = 10
SELECT t1.*
FROM dbo.TBLINSA_SH_FINAL AS t1 WITH(NOLOCK)
INNER JOIN (
SELECT insaseq
FROM dbo.TBLINSA_SH_FINAL WITH(NOLOCK)
ORDER BY salary DESC , ibsadate DESC
OFFSET (@PAGE_NUM - 1) * @PER_PAGE_ROW ROWS
FETCH NEXT (@PER_PAGE_ROW) ROWS ONLY
) AS t2
ON t1.insaseq = t2.insaseq

i/o 가 기존과 비교해서 확연한 차이를 보이는 것을 알 수 있다.
이것은 위에 도식화해놓은 것처럼 부분 처리를 활용하여 필요한 만큼의 데이터만 뽑아와서
clustered index와 매칭 시켜주어 더 빠르게 데이터를 가져올 수 있는 것이다.
'SQL Tuning' 카테고리의 다른 글
| [MSSQL] sp_lock (0) | 2022.07.21 |
|---|---|
| SQL JOIN - HASH JOIN (0) | 2022.04.08 |
| [MSSQL] MERGE JOIN (Sorted Merge Join) (0) | 2022.04.07 |
| [MSSQL] NL JOIN(Nested Loops Join) (2) | 2022.04.06 |
| 인덱스 탐색 효율(SQL server) (0) | 2022.03.23 |