
기본 매커니즘
병합(Merge) 조인은 소트 머지(Sort Merge) 조인으로 불리기도 한다.
소트 머지 조인은 조인에 참여하는 두 집합을
조인 키(컬럼) 순서대로 정렬(sort) 한 다음에 병합(merge) 한다.
인덱스에 의해 이미 조인 키 순서대로 정렬된 집합은 정렬 없이 곧바로 조인에 참여하게 된다.
일대다(One-to-Many) 관계를 맺고 있는 두 테이블 간에 병합 조인이 처리되는 과정을
pseudo 코드로 나타내면 아래와 같다.
/*일대다 병합 조인 시*/
양쪽 집합을 조인 키 순서대로 정렬한다.
(* 인덱스를 통해 정렬된 집합을 곧바로 얻을 수 있는 쪽은 이 과정이 필요없다.)
outer 집합에서 첫 번째 로우 o를 가져온다.
inner 집합에서 첫 번째 로우 i를 가져온다.
while(양쪽 집합 중 어느 것도 EOF 에 도달하지 않음)
begin
if o와 i가 조인에 성공하면
begin
조인에 성공한 로우를 리턴한다.
inner 집합에서 다음 로우 i를 가져온다.
end
else if o가 i보다 작으면
begin
outer 집합에서 다음 로우o를 가져온다.
end
else
begin
inner 집합에서 다음 로우 i를 가져온다.
end
end
MERGE JOIN 의 수행과정 분석
MERGE JOIN 예시를 위해 아래와 같은 두 테이블을 보자.

SELECT
tsfl.svc_nation_cd
, tsfl.kind
FROM dbo.TBLINSA_SH_FINAL tsf WITH(NOLOCK)
INNER LOOP JOIN dbo.TBLINSA_SH_FINAL_LOG tsfl WITH(NOLOCK) ON tsf.insaseq = tsfl.insaseq
WHERE tsfl.svc_nation_cd = 'SG'
위와 같이 간단한 쿼리인데도 TBLINSA_SH_FINAL_LOG 테이블에서는
NL JOIN의 키 컬럼을 선행으로 하는 컬럼 자체가 없으므로 랜덤액세스가 심하게 수반하게 되고
위와같이 18분이 지나도 결과를 내지 못하는 모습을 볼 수 있다.
NESTED LOOPS JOIN 같은 경우에는 OUTER 집합을 기준으로
INNER 테이블의 인덱스를 반복적으로 탐색해야 하므로
EXCUTES 수가 병합조인에 비해서 비약적으로 높아지게 된다.
이러한 이유 때문에 병합조인을 수행할때보다 더 많은 I/O가 발생될 수 있다.
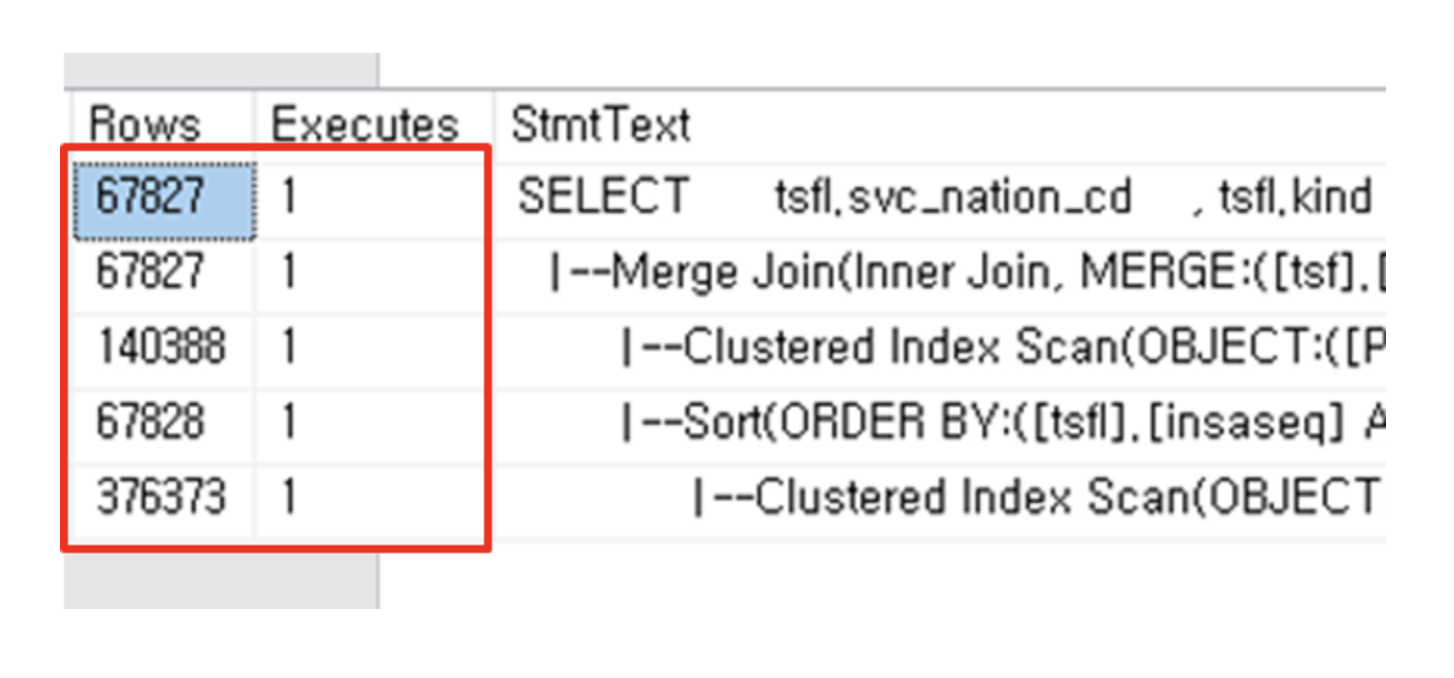
그럼 위의 쿼리를 MERGE JOIN방식을 사용해서 쿼리해보자
SELECT
tsfl.svc_nation_cd
, tsfl.kind
FROM dbo.TBLINSA_SH_FINAL tsf WITH(NOLOCK)
INNER MERGE JOIN dbo.TBLINSA_SH_FINAL_LOG tsfl WITH(NOLOCK) ON tsf.insaseq = tsfl.insaseq
WHERE tsfl.svc_nation_cd = 'SG'
NL JOIN 을 수행할때에는 18분을 기다려도 수행하지 못했지만
MERGE JOIN을 사용하니 0.2초만에 쿼리가 완료된 것을 알 수 있다.
MERGE JOIN은 양쪽 테이블을 한 번씩 액세스 하고서 메모리에서 비교한다.
일대 다 병합 조인의 내부적인 수행 과정은
OUTER 집합을 따라 내려가면서 NL 조인을 반복하는 듯한 모습이다.
NL조인은 OUTER 집합을 기준으로
INNER 테이블의 인덱스를 반복적으로 탐색하지만,
병합 조인은 양쪽 집합을 메모리 안에 정렬하고서
OUTER 집합을 기준으로 INNER 집합을 탐색한다.
NL 조인은 이미 만들어진 인덱스를 사용하는 반면에
병합 조인은 쿼리 '실행중'에 정렬 구조체를 직접 만들어서 사용한다.
또한 해당 정렬 구조체는 쿼리가 끝나면 사라지게 된다.

실행계획의 순서는 위와 같다. 실행 순서는 NL JOIN 과 다를바 없지만
각 테이블을 한번만 액세스 하고서 메모리에서
비교하는 것이 큰 차이점이다. (NL JOIN 에서는 OUTER 집합의 건수만큼 INNER 테이블을 반복해서 액세스함)
이는 병합 조인의 장점 중 하나이다.
실행순서를 하나하나 자세히 들여다보면 아래와 같다.
1) TBLINSA_SH_FINAL_LOG 테이블을 svc_nation_cd = 'SG' 조건으로 필터링 한다.
단 현재 svc_nation_cd 컬럼을 선두로 하는 인덱스가 없으므로
CLUSTERED INDEX SCAN을 통해 테이블을 전체 액세스한 후에 데이터를 가져온다.
2) TBLINSA_SH_FINAL_LOG 테이블은 현재 PK 컬럼이 test_seq 이므로
테이블의 정렬순서는 test_seq 기준으로 정렬되어 있다.
SORTED MERGE JOIN을 위해서는 현재 JOIN KEY 인 insaseq 를 기준으로 데이터를 정렬시켜야한다.
3) TBLINSA_SH_FINAL 테이블을 CLUSTERED INDEX SCAN 한다.
현재 해당 테이블의 PK 컬럼은 insaseq 이므로 정렬이 되어 있는 상태이다.
4) 정렬된 TBLINSA_SH_FINAL_LOG 테이블 내의 데이터와
TBLINSA_SH_FINAL 테이블을 병합 방식으로 조인한다.
5) 병합한 결과를 토대로 원하는 데이터를 가져온다.
위의 실행계획에서 눈여겨 봐야할 점은
일반적인 NL 조인에 비해 INNER 집합쪽을 반복적으로 탐색하지 않는다는 것이다.
또한 각 테이블을 조인조건의 컬럼으로 정렬할때 동시에 정렬한다.(다중쓰레드 와 같은 방식으로)
예를들어 NL JOIN 의 실행계획은 OUTER 집합에서 N 건을 읽으면
INNER 집합에서 해당 N건만큼 반복적으로 접근한다.
(논리적 읽기가 비약적으로 많이 발생하게 됨)
(아래의 사진이 NL JOIN 의 방식)

하지만 SORTED MERGE JOIN을 사용하였을 때는 처음에 테이블을 스캔하지만,
OUTER 집합의 개수를 기준만큼 INNER 테이블에 액세스하는 작업이 없어지므로
NL JOIN 만큼의 성능부하를 일으키지 않는다.
(아래의 사진이 SORTED MERGE 의 방식)
위의 실행계획을 도식화 하면 아래와 같다.

다대다(MANY-TO-MANY) 병합조인 분석
병합 조인에서도 조인 순서는 매우 중요하다.
병합 조인에 참여하는 두 테이블이 물리적으로 1:M 관계일 때 조인이
1 -> M 순서로 진행되면 ONE-TO-MANY 병합조인 이라고 한다.
OUTER 집합에 중복된 조인 키가 없으므로
INNER 집합에서 같은 범위를 다시 액세스하지 않는다.
OUTER 집합에서 한 건씩 가져와 INNER 집합을 정렬된 순서대로 읽어 가다가
조인에 성공하면 데이터를 출력하고 실패하면 다음로우로 내려간다.
OUTER 쪽은 한 건씩 읽어 내려가면 그만이고
INNER 쪽은 조인에 실패한 지점만 표시하면 된다.
다음 OUTER 입력 값은 INNER 쪽에 마지막으로 표시된 시작점부터 조인을 시작한다.
병합조인이 M:M 관계일때도 OUTER 집합에서 한 건씩 가져와서
INNER 집합을 정렬된 순서로 읽어나간다.
하지만, 1 : M 방식 처럼 INNER 집합에 조인이 실패한 지점을 표시한다 해도
OUTER 집합에서 또 같은 데이터를 INNER 집합에서 액세스 해야하므로
INNER 집합의 특정 구간을 중복적으로 읽는 경우가 발생한다.
이를 방지하기 위해 옵티마이저는 M:M 조인방식에서는 OUTER 집합과
조인에 성공한 INNER 집합의 로우를 TEMPDB 에 존재하는 임시테이블에 복사해놓는다.
그 다음 OUTER 집합에서 같은 값이 나타나면
INNER 집합을 탐색하는 대신 임시테이블을 액세스한다.
반면, 다른 값이 나타나면 임시 테이블에 저장된 로우를 버리고 INNER 집합을 탐색한다.
또한 물리적으로 1:M 관계라도 병합 조인이 M->1 순서대로 진행되면
OUTER 집합의 중복된 값이 INNER 집합의 같은 범위를 여러 번 탐색하는 비효율이 발생할 수 있다.
이렇게 M->1 순서로 진행되는 병합조인에서도 마찬가지로 M:M 병합조인 방식과 동일하게 작동한다.
1) 1:M 병합조인

2) M:M 병합조인

M : 1, M : M 병합 조인을 시도하면 실행계획의
MERGE JOIN 오퍼레이션에 'MANY-TO-MANY' 가 표시된다.
그리고 트레이스 결과에 'Worktable' 에 대한 스캔 수와 논리적 읽기 수 등이 나타난다.
1 : M 조인보다 M : 1 조인이나 M : M 조인의 성능이 불리한 이유는
임시테이블을 의미하는 Worktable 의 I/O 가 상당히 크기 때문이다.
중복되는 구간의 INNER 테이블의 정보를 TEMPDB 에 임시테이블에 저장해놓기 때문에
해당 정보를 액세스하기 위해서는
I/O의 수가 늘어나는 것은 당연하고 결국 성능적으로 효율이 좋지 못하게 된다.
예를들어 아래와 같이 pack_no 는 현재 유일하지 않은 데이터들이 분산되어 있는 컬럼이다.
해당 컬럼자체로 INNER MERGE JOIN을 수행하게 되면
M:M MERGE JOIN 이 되기 때문에 실행계획에 MANY-TO-MANY
오퍼레이션이 표시되게 된다.
MANY-TO-MANY 오퍼레이션이 나타났으므로
TEMPDB 에 WORKTABLE 이 쓰인것을 알 수 있다.
SELECT
tds1.insaseq
, tds1.pack_no
FROM dbo.TBLINSA_DETAIL_SH tds1 WITH(NOLOCK)
INNER MERGE JOIN dbo.TBLINSA_DETAIL_SH tds2 WITH(NOLOCK) ON tds1.pack_no = tds2.pack_no
MERGE JOIN 실습
실습을 위해 아래와 같이 쿼리해보자.
SELECT TOP 100000
IDENTITY(INT,1,1) AS student_id
, CAST(ABS(a.id) % 101 as SMALLINT) as studnet_score
, cast(' ' as varchar(1)) as grade_code , a.*
INTO dbo.STUDENT
FROM MASTER.dbo.SYSCOLUMNS a
, MASTER.dbo.SYSINDEXES b
CREATE TABLE dbo.GRADETBL
(
grade_code varchar(1) not null
, start_score smallint
, end_score smallint
)
INSERT INTO dbo.GRADETBL
SELECT 'A',90,100
UNION ALL
SELECT 'B',75,89
UNION ALL
SELECT 'C',60,74
UNION ALL
SELECT 'D',50,59
UNION ALL
SELECT 'F',0,49
ALTER TABLE dbo.GRADETBL ADD CONSTRAINT PK__GRADETBL__GRADE_CODE PRIMARY KEY (grade_code)
CREATE INDEX IDX__GRADETBL__START_SCORE__END_SCORE ON dbo.GRADETBL (start_score,end_score)
--결과
SELECT * FROM dbo.STUDENT WITH(NOLOCK)
SELECT * FROM dbo.GRADETBL WITH(NOLOCK)
위의 그림을 보면 STUDENT 의 테이블이 현재 grade_code 의 값이 채워져 있지 않으므로
해당 학생들의 student_score을 바탕으로 GRADETBL 에서 점수를 맵핑해보자.
student_score 가 95면 A GRADE 를 맵핑해주는 방식
INNER JOIN 방식으로 아래와 같이 간단한 로직을 사용해서 쿼리할 수 있다.
UPDATE s
SET s.grade_code = g.grade_code
FROM dbo.STUDENT s
INNER JOIN dbo.GRADETBL g ON s.studnet_score BETWEEN g.start_score AND g.end_score
OUTER 테이블이 10만건이므로 JOIN을 하면서
INNER 테이블을 액세스 할때 10만번 액세스하는것을 볼 수 있다.
10만번의 랜덤액세스는 I/O 를 많이 잡아먹기 마련이다.
해당 로직을 SORTED MERGE JOIN을 사용하여 I/O 를 줄여보도록 하자.
DROP TABLE #SCORE_INDEX
SELECT TOP 101
IDENTITY(SMALLINT,0,1) AS score
INTO #SCORE_INDEX
FROM master.dbo.SYSCOLUMNS
UPDATE st
SET st.grade_code = sb.grade
FROM
(
SELECT s.score, MAX(g.grade_code) AS grade
FROM dbo.GRADETBL g WITH(NOLOCK)
INNER JOIN #SCORE_INDEX s WITH(NOLOCK) ON s.score >= g.start_score AND s.score <= g.end_score
GROUP BY s.score
) sb
INNER MERGE JOIN dbo.STUDENT st ON sb.score = st.studnet_score

먼저 점수는 0~100 사이의 정수이므로 IDENTITY() 함수를 사용해서
임시테이블인 #SCORE_INDEX 테이블을 생성해준다.
그리고 해당 테이블에 101가지 점수 값을 저장한다.
#SCORE_INDEX 테이블과 GRADETBL 테이블을 조인하면
(0,F),(1,F)......(99,A),(100,A) 인 인라인뷰가 만들어진다.
물론 해당 인라인뷰자체를 STUDENT 테이블과 조인해서 결과를 얻을 수 있겠지만
인라인뷰 자체에 UNIQUE 조건이 없으므로 M->M 병합조인으로 처리된다.
이렇게 되면 임시테이블을 사용하는등 I/O 가 커지게 되고 자연스럽게 성능이 하락하게 된다.
이를 방지하기 위해서, 1->M 이라는것을 보장해줄 수 있는 GROUP BY 나
DISTINCT 를 사용하면 옵티마이져는 해당 조인을 1->M 으로 인식하게 되어
효율적인 SORTED MERGE JOIN (1->M) 을 수행할 수 있다.
MERGE JOIN 요약
Sorted Merge Join 은 다음과 같은 특징이 있다.
첫째, 양쪽 집합을 정렬하고서 조인한다.
NL 조인은 outer 테이블부터 시작해 한 로우씩 차례대로 inner 테이블을 탐색하지만,
병합조인은 양쪽 테이블을 한 번에 읽어서 비교해 나간다.
조인에 참여하는 두 집합을 조인 키 순서대로 정렬한 다음에 병합한다.
따라서 양쪽 집합이 인덱스에 의해 이미 정렬된 상태라면 가장 효율적인 조인 방식이지만,
정렬 작업이 필요한 경우에는 큰 비용이 발생할 수 있다.
둘째, 테이블별 검색조건에 따라 전체 일량이 좌우된다.
NL 조인은 OUTER 테이블에서 얻은 조인 컬럼 값으로 INNER 테이블을 탐색하므로
먼저 액세스한 테이블의 처리 범위에 따라 전체 일량이 결정된다.
그러나 병합 조인은 각 테이블을 독립적으로 액세스하므로 테이블별 검색조건에 따라 전체 일량이 좌우된다.
셋째, 랜덤 액세스 위주로 수행되지 않는다.
병합 조인의 트레이스 결과에 나타난 것처럼, 양쪽 테이블의 검색 수는(EXECUTES) 모두 1이다.
병합 조인은 INNER 테이블을 반복적으로 탐색하지 않으므로
정렬된 집합을 병합하는 과정에서 랜덤 액세스가 발생하지 않는다.
그러나 각 테이블로부터 대상 로우를 추출하는 과정에서는
북마크 룩업에 의한 랜덤 액세스가 대량으로 발생할 수 있다.
넷째, 다대다(MANY-TO-MANY) 조인보다는 일대다(ONE-TO-MANY) 조인에서 효과적이다
기본적으로 UNIQUE 인덱스 등의 물리적 제약이 없으면 일대다 관계를 보장할 수 없다.
그러나 물리적으로 다대다 관계일지라도 업무적 또는 논리적으로는 일대다 관계일 떄가 있다.
이때는 1쪽 집합이 되는쪽에 GROUP BY, DISTINCT 등의 연산자를 사용하여
일대다 조인으로 유도하면 성능을 높일 수 있다.
'SQL Tuning' 카테고리의 다른 글
| [MS SQL] 페이징 처리 최적화 (0) | 2022.07.19 |
|---|---|
| SQL JOIN - HASH JOIN (0) | 2022.04.08 |
| [MSSQL] NL JOIN(Nested Loops Join) (2) | 2022.04.06 |
| 인덱스 탐색 효율(SQL server) (0) | 2022.03.23 |
| 북마크 룩업 최소화 기법(3) - Covered Index (0) | 2022.01.29 |