
HASH JOIN 이란?
1. 기본 메커니즘
NL 조인은 인덱스를 이용한 조인 방식이므로 인덱스 구성에 따른 성능 차이가 심하다.
또한 인덱스를 아무리 완벽히 구성해도 랜덤 I/O 때문에 대량 데이터 처리에 불리하고
버퍼캐시 히트율에 따라 들쭉날쭉한 성능을 보인다.
소트 머지 조인과 해시 조인은 조인 과정에서 인덱스를 이용하지 않기 때문에
대량 데이터를 조인할 때 NL 조인보다 훨씬 빠르고, 일정한 성능을 보인다.
소트 머지 조인은 항상 양쪽 테이블을 정렬해야 하는데, 해시 조인은 그런 부담도 없다.
일반적으로 HASH JOIN은 아래의 알고리즘을 적용하여 조인을 수행한다.
작은 집합으로 해시 테이블을 생성하고 큰 집합을 읽으면서 해시 테이블을 탐색한다.
해시 테이블을 만드는데 사용되는 집합을 Bulid Input이라 하고
탐색하는 데 사용되는 집합을 Probe Input이라고 한다.
1) Build 단계 : 작은 쪽 테이블(Build Input)을 스캔해서 해시 테이블(해시 맵)을 생성한다.
2) Probe 단계 : 큰 쪽 테이블(Probe Input)을스캔해서 해시 테이블을 탐색하면서 조인한다.

Hash Join 에서 HASH 함수란 특정 입력 값에 대해 일관된 출력 값을 보장해 주는 함수이다.
즉 HASH 함수 F(x)가 존재한다고 해보자.
매개변수 x 에 3이 들어가면 9 가 나오는 것이고
매개변수에 5 가 들어가면 35 가 나오는데,
어쩔때는 3 이 들어갈 때 9가 나오고 또 다른 때는 10이 나오면 안 된다는 것이다.
해시함수는 중요한 정보를 해시함수로 저장하여 복원이 불가능하게 만들어
해당 정보를 다시 해시함수로 바꾸었을때 그 정보가
맞는지를 판단하게 해주려는 의도로 만들어졌다.
해시함수는 단방향 암호화 함수로 역함수가 존재해서는 안된다는 것이다.
결국 단사조건(일대일 함수)을 만족하면 안 되고 더 나아가
전단사 함수(일대일 대응)가 되면 안되는 것이다.
즉, Surjective Function (전사함수) 만을 만족해야 Hash Function이 된다는 것이다.

- Hash Function도 전사함수이기 때문에 Hash Collision
(해쉬충돌 = 특정 2개 이상의 정의역의 상이 같은 경우) 이 일어날 수 있는데,
해쉬 충돌이 발생하면입력 값이 다른 엔트리가 하나의 해쉬 버킷(Hash Bucket)에 들어가게 된다.
위의 그림에서는 정의역 3,4 -> C 상으로 맺히므로 해당 상황을 해쉬충돌이 발생했다고 할 수 있다.
- 해쉬 버킷에 들어갈 때 해쉬 값이 같은 입력 값들은 체인(Linked List)으로 연결된다.
- 해쉬 테이블은 해쉬버킷으로 구성된 배열이라고 생각하면 된다.
HASH JOIN의 종류
HASH JOIN 은 약 4종류가 존재한다.
1. In-Memory Hash Join
2. Grace Hash Join (유예 해쉬 조인)
3. Recursive Hash Join (= Nested Loops Hash Join) (재귀 해쉬 조인)
4. Hybrid Hash Join
1. In-Memory Hash Join
Hash Table을 메모리에 유지할 수 있는 경우의 조인 방법이다.(Hash Table 자체가 크지 않아야 한다.)
해쉬 함수를 이용해서 Build Input을 읽어 해쉬 테이블을 생성한다.
Hash Table에는 Hash Key와 결과에 출력될 칼럼들이 저장된다.
해쉬함수를 통하여 Probe Input을 스캔하여 읽은 데이터로 Hash Table을 탐색한다.
즉, 해쉬 값으로 버킷을 찾아가 해쉬 체인을 스캔하며 데이터를 탐색한다.
2. Grace Hash Join (유예 해쉬 조인)
해쉬 테이블 크기 자체가 메모리가 할당 가능한 크기보다 커서
보조 디스크의 도움을 받아야 할 경우의 조인 방법으로
파티션 단계와 조인 단계 두 단계로 나누어 진행된다.
Grace Hash Join은 파티션 단계에서 양쪽 집합을 모두 읽어서 TempDB에 저장해야 하므로
In-Memory Hash Join 보다 성능이 크게 떨어진다.
1) 파티션 단계
- where 조건으로 양쪽 두 테이블을 필터링 해준다.
- Hash Function을 적용하여 value에 따라 파티셔닝 한 후에
각각의 파티션 별로 Tempdb에 임시 파일로 저장해 준다.
- 각 테이블에는 동일한 Hash Function을 적용해 준다. 즉, 같은 해쉬 키를 기반으로 파티션 된다.
이러한 작업으로 인해 같은 해쉬 키를 가진 두 파티션을 partition pair라고 부른다.
2) 조인 단계
- partition pair에서 한쪽의 파티션 파일에 대해 Hash Function을
적용하여 Hash Table을 생성해 준다.
Hash Join은 기본적으로 Build Input과 Probe Input 이 수반되어야 하는데,
이는 옵티마이저의 판단에 따라 Build Input , Probe Input으로 지정할 테이블이 정해진다.
- partition pair에서 반대쪽 partition 파일의 row를 하나씩 읽어가며 Hash Table을 탐색한다.
- 모든 파티션 pair에 대한 처리가 완료될 때까지 이 과정을 반복한다.

3. Recursive Hash Join (= Nested Loops Hash Join) (재귀 해쉬 조인)
TempDB에 있는 partition pair 끼리 조인을 수행하려고 더 작은 파티션을 메모리에 올리는
과정에서도 메모리 가용범위를 초과하게 된다면, 추가적인 파티셔닝 단계를 수행한다.
4. Hybrid Hash Join
In-Memory Hash Join과 Grace Hash Join요소가 결합되어 조인한다.
2. HASH JOIN의 수행과정 분석
해시조인을 수행하는 쿼리를 직접 보면서 이해해 보자.
아래 두 테이블을 사용해서 조인시켜 보자

SELECT
tsf.insaseq
, tsf.name
, tds.pack_no
FROM dbo.TBLINSA_SH_FINAL tsf WITH(NOLOCK)
INNER JOIN dbo.TBLINSA_DETAIL_SH tds WITH(NOLOCK) ON tsf.insaseq = tds.insaseq

우선 작은 쪽 테이블인 TBLINSA_DETAIL_SH 테이블(78574건)을 스캔하여 해시 테이블을 생성한다.(BUILD 단계)

그다음 큰 쪽 테이블인 TBLINSA_SH_FINAL 테이블(140,388건)을 스캔해서
해시 테이블을 탐색하며 조인한다. (PROBE 단계)
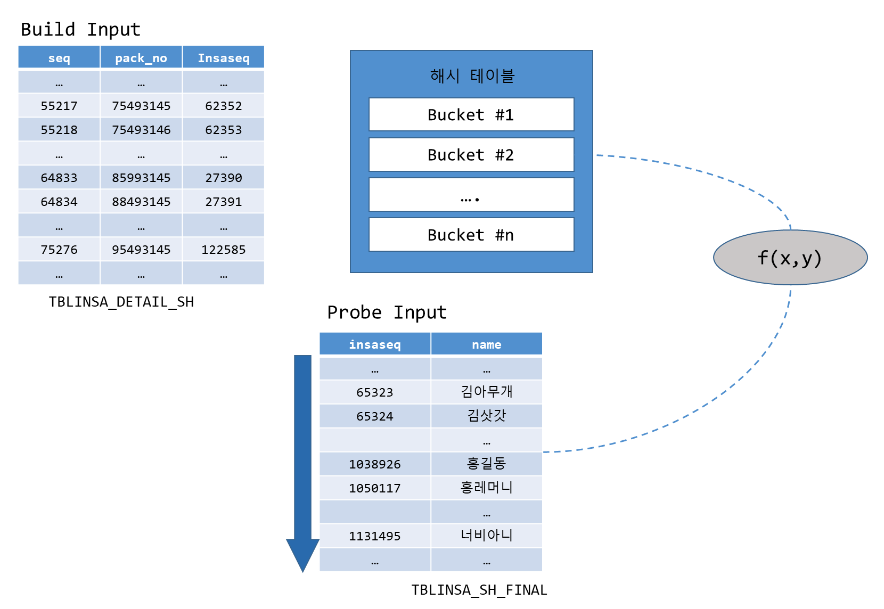
해시 조인은 해시 테이블을 구성하는 Build Input의 크기가 성능에 큰 영향을 미친다.
Build Input이 가용 메모리보다 작으면 해시 테이블을 메모리 안에 생성한다.
이렇게 메모리 안에서 한 번에 처리되는 방식을 인-메모리 (In - Memory) 해시 조인이라고 한다.
만약 Build Input이 가용 메모리를 초과하면 유예 (Grace) 해시 조인
또는 재귀 (Recursive) 해시 조인으로 수행되는데
인-메모리 해시 조인과 달리 집합을 분할하여 단계적으로 조인하는 복잡한 과정을 거친다.
이때 TempDB를 사용하므로 인-메모리 해시 조인보다 성능이 크게 떨어진다.
정말 Build Input의 크기가 성능에 영향을 미치는지 예제를 보면서 이해해 보자.
현재 예시를 위한 테이블인 TBLINSA_SH_FINAL의 데이터는 약 80만 건이 존재하고,
TBLINSA_DETAIL_SH_FIRST 테이블에는 약 1000건의 데이터가 존재한다.
1. 큰 집합을 먼저 액세스 한 경우
SELECT
tsf.insaseq
, tsf.name
, tdsf.pack_no
FROM dbo.TBLINSA_SH_FINAL tsf WITH(NOLOCK)
INNER HASH JOIN dbo.TBLINSA_DETAIL_SH_FIRST tdsf WITH(NOLOCK) ON tsf.insaseq = tdsf.insaseq
2. 작은 집합을 먼저 액세스 한 경우
SELECT
tsf.insaseq
, tsf.name
, tdsf.pack_no
FROM dbo.TBLINSA_DETAIL_SH_FIRST tdsf WITH(NOLOCK)
INNER HASH JOIN TBLINSA_SH_FINAL tsf WITH(NOLOCK) ON tsf.insaseq = tdsf.insaseq
논리적 읽기 등 I/O 측면에서는 다른 게 없지만 어떤 테이블이 Build Input 이 되느냐에 따라
CPU TIME 이달라진 것을 볼 수 있다.
즉 Hash Join 도 Nested Loop Join과 마찬가지로
구동테이블의 크기가 작을수록성능이 좋아지게 된다.
3. Nested Loops, Sorted Merge, Hash의 수행과정 비교
그럼 만약 INDEX 가 없는 상태에서 NESTED LOOPS JOIN, MERGE JOIN, HASH JOIN의 성능이
얼마나 차이 나는지 확인해 보자.
Nested Loops Join
SELECT
tsf.insaseq
, tsf.name
, tdsf.pack_no
FROM dbo.TBLINSA_SH_FINAL tsf WITH(NOLOCK)
INNER JOIN dbo.TBLINSA_DETAIL_SH tdsf WITH(NOLOCK) ON tsf.insaseq = tdsf.insaseq
OPTION(LOOP JOIN)
인덱스가 없는 상태에서의 Nested Loops Join은 랜덤액세스를 계속 수반하는데,
적절한 인덱스도 없기 때문에 엄청나게 비 효율적인 실행계획을 생성하게 된다.
(2분이 넘어서도 쿼리가 끝나질 않음)
Sorted Merge Join
SELECT
tsf.insaseq
, tsf.name
, tdsf.pack_no
FROM dbo.TBLINSA_SH_FINAL tsf WITH(NOLOCK)
INNER JOIN dbo.TBLINSA_DETAIL_SH tdsf WITH(NOLOCK) ON tsf.insaseq = tdsf.insaseq
OPTION(MERGE JOIN)

SORTED MERGE 같은 경우에는 인덱스가 없더라도
두 테이블을 모두 정렬작업을 거친 후에 조인시키므로 Nested Loops Join 만큼의 비효율이 나타나지는 않는다.
하지만 여전히 Sorting 작업으로 인한 성능하락을 의심할 수 있고
더욱 중요한 건 1 : M 조인 조건이 아니라 M : M 조인 조건이라 비효율이 나타나는 것을 알 수 있다.

Hash Join
Merge Join을 하기에는 테이블의 크기가 너무 크거나 M : M 관계인 경우 Hash Join을 사용하면
쿼리의 효율을 더 끌어올릴 수 있다.
SELECT
tsf.insaseq
, tsf.name
, tdsf.pack_no
FROM dbo.TBLINSA_DETAIL_SH tdsf WITH(NOLOCK)
INNER HASH JOIN TBLINSA_SH_FINAL tsf WITH(NOLOCK) ON tsf.insaseq = tdsf.insaseq

CPU 실행시간이 Sorted Merge Join을 수행할 때보다 더욱 줄어든 모습을 볼 수 있다.
4. Hash Join 요약
해시 조인의 특징을 종합하면 다음과 같다.
1. 조인 대상 집합을 정렬할 필요가 없다.
Sort Merge 조인과는 달리, 조인에 참여하는 두 집합을 정렬하지 않는다.
바로 이 특징 때문에 대량 데이터 조인 시 위력을 발휘한다.
(Sort Merge 조인도 대량 데이터 조인에 활용되지만,
조인 키에 인덱스가 없으면 정렬하는 데 큰 비용이 발생한다.)
그러나 정렬 연산이 불필요한 대신, 해시 테이블 생성과 탐색에 많은 자원을 사용하므로
OLTP 환경에서는 주의가 필요하다.
2. 테이블별 검색조건에 따라 전체 일 량이 좌우된다.
NL 조인은 outer 테이블에서 얻은 조인 칼럼 값으로 inner 테이블을 탐색하므로
먼저 액세스 한 테이블의 처리 범위에 따라 전체 일 량이 결정된다고 했다.
그러나 해시 조인은 각 테이블을 독립적으로 액세스 하므로 테이블별 검색조건에 따라 전체 일량이 좌우 된다.
3. 랜덤 엑세스 위주로 수행되지 않는다.
해시 조인은 조인 과정에서 랜덤 액세스가 발생하지 않는다.
inner 집합의 로우가 해시 테이블을 탐색하기는 하지만,
이는 메모리에 생성된 구조체를 액세스 하는 것이므로
흔히 말하는 랜덤 액세스와는 다르다.
하지만, 각 테이블로부터 대상 로우를 추출하는 과정에서는
룩업에 의한 랜덤 액세스가 대량으로 발생할 수 있으므로 주의해야 한다.
4. 조인 칼럼의 인덱스 유무가 조인 속도에 영향을 미치지 않는다.
NL 조인과 Sort Merge 조인은 조인 연결고리의 인덱스가 조인 속도에 큰 영향을 미친다.
그러나 해시 조인은 해시 함수의 결과 값으로 조인하므로
조인 연결고리에 인덱스가 없어도 조인 과정에 아무런 문제가 없다.
'SQL Tuning' 카테고리의 다른 글
| [MSSQL] sp_lock (0) | 2022.07.21 |
|---|---|
| [MS SQL] 페이징 처리 최적화 (0) | 2022.07.19 |
| [MSSQL] MERGE JOIN (Sorted Merge Join) (0) | 2022.04.07 |
| [MSSQL] NL JOIN(Nested Loops Join) (2) | 2022.04.06 |
| 인덱스 탐색 효율(SQL server) (0) | 2022.03.23 |