
인덱스 탐색 효율(SQL server)
인덱스 탐색 과정에 비효율이 있다면 이를 제거하기 위하여 노력해야 한다.
옵티마이저는 인덱스를 수직으로 탐색하고 나서 리프 페이지를 수평으로 읽어 나갈 때 시퀀셜 엑세스 방식을 사용한다.
이 엑세스 방식이 랜덤 엑세스보다 상대적으로 빠르기는 하지만 불필요하게 넓은 범위를 엑세스하면
인덱스 탐색 효율에 문제가 생긴다.
인덱스 탐색 효율을 개선하고자 할 때, 기존 인덱스에 칼럼을 추가하거나 클러스터형 인덱스로 변경하는 등의 방법은
별로 도움되지 않는다.
인덱스 탐색 효율에 큰 영향을 미치는 것은 '인덱스 키 칼럼 순서'와 '검색 조건에 사용된 연산자'이다.
1. 모든 칼럼에 equal 조건을 사용했을 때
아래와 같은 테이블이 존재한다고 가정해보자.
ALTER TABLE dbo.TBLINSA_SH_TEST ADD CONSTRAINT PK__TBLINSA_SH_TEST__OID PRIMARY KEY (oid)
SELECT * FROM dbo.TBLINSA_SH_TEST WITH(NOLOCK)

IDX__TBLINSA_SH_TEST__OP_ID__CHG_DT 인덱스와 IDX__TBLINSA_SH_TEST__CHG_DT__OP_ID 인덱스를 구성하였다.
인덱스는 구성이 같으나, 순서가 다르다는 점에 주목해야 한다.
CREATE INDEX IDX__TBLINSA_SH_TEST__OP_ID__CHG_DT ON dbo.TBLINSA_SH_TEST (op_id,chg_dt)
CREATE INDEX IDX__TBLINSA_SH_TEST__CHG_DT__OP_ID ON dbo.TBLINSA_SH_TEST (chg_dt,op_id)
검색 조건은 같지만 서로 다른 인덱스를 사용하게끔 힌트를 추가한 두 쿼리를 작성 하였다.
SELECT * FROM dbo.TBLINSA_SH_TEST WITH(NOLOCK,INDEX(IDX__TBLINSA_SH_TEST__OP_ID__CHG_DT))
WHERE op_id = 'chchoing'
AND chg_dt = '2015-07-14 20:51:50.747'
SELECT * FROM dbo.TBLINSA_SH_TEST WITH(NOLOCK,INDEX(IDX__TBLINSA_SH_TEST__CHG_DT__OP_ID))
WHERE op_id = 'chchoing'
AND chg_dt = '2015-07-14 20:51:50.747'
아래를 보면 두 쿼리의 성능차에 대해서 알 수 있다.
두 쿼리의 비용은 각각 50%로 똑같다.
두 쿼리의 성능이 같은 이유를 알아보자. 인덱스 구성 칼럼과 검색조건이 같으므로 북마크 룩업 과정은 차이가 없다.
인덱스 탐색 과정만 살펴보면 된다.
어느 인덱스를 탐색하더라도 엑세스 범위는 같다.
즉 인덱스 탐색의 전체 일량에도 아무런 차이가 없다.
모든 인덱스 칼럼에 equal 조건을 사용하면 인덱스를 가장 효율적으로 탐색하게 된다.
만약 인덱스 키 칼럼을 항상 equal 조건으로 검색한다면 인덱스 칼럼 순서를 심각하게 고민할 필요가 없다.
2. 선행 칼럼에 between 조건을 사용했을 때
이번에는 앞에서 생성한 인덱스를 그대로 두고 쿼리만 조금 변경하였다, (between 사용)
SELECT * FROM dbo.TBLINSA_SH_TEST WITH(NOLOCK,INDEX(IDX__TBLINSA_SH_TEST__OP_ID__CHG_DT))
WHERE op_id = 'chchoing'
AND chg_dt BETWEEN '2010-07-01' AND '2022-01-01'
SELECT * FROM dbo.TBLINSA_SH_TEST WITH(NOLOCK,INDEX(IDX__TBLINSA_SH_TEST__CHG_DT__OP_ID))
WHERE op_id = 'chchoing'
AND chg_dt BETWEEN '2010-07-01' AND '2022-01-01'


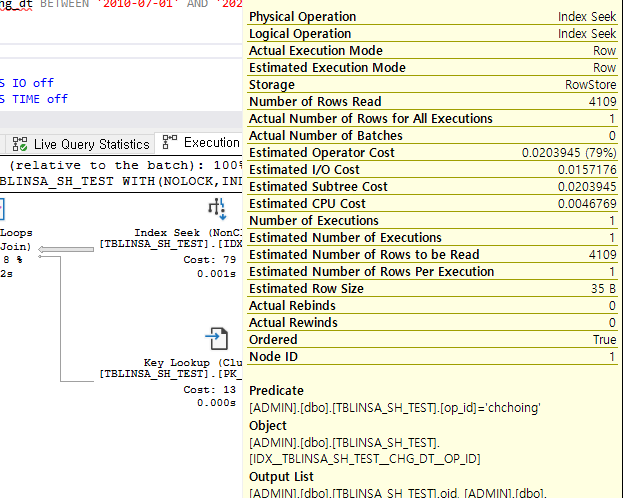
쿼리의 비용 자체가 많이 나는 것을 볼 수 있다 똑같이 인덱스를 통하여 SEEK 해서 데이터를 가져오고 있지만
SEEK 하는 부분의 I/O 자체가 다른것을 볼 수 있다.
현재 테이블에서는 데이터가 많이 없어서 큰 차이로 보여지지 않지만 만약에 데이터가 수십만건 수백만건이 된다면
I/O 가 4.5 배가 차이난다는것은 매우 큰 차이이다.
이렇게 큰 성능 차이가 발생한 이유를 알아보기 위해
도식화한 두 쿼리의 인덱스 탐색 과정을 비교해서 나타냈다.

두 쿼리의 인덱스 엑세스 범위에 큰 차이가 있다.
왼쪽 IDX__TBLINSA_SH_TEST__OP_ID__CHG_DT 인덱스는 필요한 범위만 엑세스 하여 데이터를 추출한다.
인덱스 선두 칼럼에 equal 조건을 사용 했으므로, 두 번째 컬럼 (=chg_dt)이 인덱스 엑세스 범위를 결정하게 된다.
보다시피 IDX__TBLINSA_SH_TEST__OP_ID__CHG_DT 인덱스는 탐색하는 과정에서 비효율이 전혀 없다.
반면에 오른쪽을 보면, IDX__TBLINSA_SH_TEST__CHG_DT__OP_ID 인덱스에서 불필요하게 넓은 범위를 엑세스한다.
인덱스 선두 칼럼인 chg_dt 칼럼에 between 조건을 사용했으므로 op_id 칼럼은 필터 역할 밖에 할 수 가 없다.
IDX__TBLINSA_SH_TEST__CHG_DT__OP_ID 인덱스는 탐색하는 과정에서 검색조건에 해당하지 않은 로우까지
모두 읽고 버리는 비효율이 있다.
1) IDX__TBLINSA_SH_TEST__OP_ID__CHG_DT 인덱스(op_id,chg_dt)
1건을 읽고 실제 1건을 조회함

2) IDX__TBLINSA_SH_TEST__CHG_DT__OP_ID 인덱스(chg_dt,op_id)
4109건을 읽고 실제 1건을 조회함
인덱스 선두 칼럼에 equal 조건을 사용하고, 두 번째 칼럼에 between 등의 조건을 사용하면,
두 번째 칼럼에 대한 검색 조건이 인덱스 탐색 일량을 결정한다.
인덱스 선두 칼럼에 between 등의 조건을 사용하면, 첫 번째 (=선두) 칼럼이 인덱스 탐색 일량을 결정하고
두 번째 칼럼은 필터링 정도의 역할만 하게 된다.
즉, 두 번째 칼럼 부터는 인덱스 탐색 일량을 줄이는 데 별 도움이 되지 않는다.