
B-TREE 구조
B-TREE 즉, 균형트리 (BALANCED TREE 줄여서 B-TREE)는
'자료구조'에 나오는 범용적으로 사용되는 데이터의 구조다.
이 구조는 주로 인덱스를 표현할 때와 그 외에서도 많이 사용된다.
이름에서 알 수 있듯이 B-TREE는 균형이 잡힌 트리다.
NODE / PAGE
노드(NODE)는 트리 구조에서 데이터가 존재하는 공간이다.
즉, 갈라지는 부분의 '마디'를 뜻한다.
1) 루트노드(ROOT NODE)
가장 상위 노드로서 모든 출발은 해당 루트 노드에서 시작된다.
2) 브랜치 노드(BRANCH NODE)
중간노드라는 의미로 루트노드와 리프노드 사이에 징검다리 역할을 수행한다.
3) 리프노드(LEAP NODE)
제일 잎 노드 말단 노드라는 의미로 마지막에 있는 노드를 말한다.
노드(NODE)라는 용어는 개념적인 설명에서 주로 나오는 용어이며,
SQL SERVER가 B-TREE를 사용할 때는 이 노드에 해당되는 것이 페이지(PAGE)이다.
페이지란 8kbyte 크기의 최소한의 저장 단위다.
아무리 작은 데이터를 한 개만 저장하더라도 한 개 페이지 8KB(=8192 바이트)를 차지하게 된다.
즉, 개념적으로는 노드라고 부르지만,
SQL SERVER 에서는 노드가 페이지가 되며 인덱스를 구현할 때 B-TREE 구조를 사용한다.
SELECT TOP(20) * INTO dbo.TBLINSATEST FROM dbo.TBLINSA
SELECT * FROM dbo.TBLINSATEST WITH(NOLOCK)

위와 같이 TBLINSATEST 테이블에 name에 인덱스를 생성하면,
이 인덱스는 어떤 모습을 가질까?
이 경우 인덱스 엔트리가 20 개에 불과하기 때문에
별다른 옵션을 지정하지 않으면 인덱스 페이지 하나에 모두 저장될 수 있다.
엔트리 개수가 너무 적어서 루트, 브랜치, 리프 페이지로 나눌 필요가 없기 때문이다.
만약 인덱스 페이지 하나마다 엔트리를 2~3개만 저장할 수 있다면
우리가 원하는 여러 갈래가 있는 B-TREE 구조가 만들어질 것이다.
(적은 개수만 저장할 수 있게 아래와 같이 옵션 지정이 필요하다.) 아래와 같이 인덱스를 생성해 보자.
CREATE INDEX IDX__TBLINSA__NAME ON dbo.TBLINSATEST (name) WITH (FILLFACTOR=1,PAD_INDEX=ON)
TBLINSATEST의 인덱스 정보를 보기 위해서 아래와 같이 쿼리 해준다.
DBCC IND를 사용해 주면 인덱스에 속한 페이지 목록을 출력할 수 있다.
명령어의 첫 번째 인자에 데이터베이스 명을,
두 번째 인자에 테이블 명을,
세 번째 인자에 인덱스 ID를 입력하면 된다.
인덱스 ID를 쿼리 하는 방법은 아래와 같다.
SELECT index_id,name FROM sys.indexes WITH(NOLOCK) WHERE object_id = object_id('TBLINSATEST')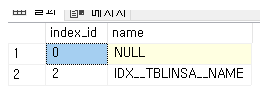
우리가 보고 싶은 인덱스는 IDX__TBLINSA__NAME 이므로 아래와 같이 쿼리 해준다.
DBCC IND('ADMIN','TBLINSATEST',2)
위의 사진에서 INDEXLEVEL 값이 0 이면 해당 페이지가 리프 노드에 있음을 의미하는데,
상위 페이지로 올라갈수록 이 값이 1만큼 증가한다.
현재는 INDEXLEVEL 값의 종류가 0,1,2 세 가지인 것으로 보아
루트 노드(2) -> 브랜치 노드(1) -> 리프 노드(0)로 구성된 형태임을 알 수 있다.
각 페이지 번호를 인자로 DBCC PAGE 명령어를 실행하면,
인덱스 페이지의 내용을 텍스트 형태로 출력할 수 있다.
DBCC TRACEON(3604)
--LEVEL 2
DBCC PAGE('ADMIN',1,170761,3)
--LEVEL 1
DBCC PAGE('ADMIN',1,170784,3)
DBCC PAGE('ADMIN',1,170760,3)
--LEVEL 0
DBCC PAGE('ADMIN',1,170744,3)
DBCC PAGE('ADMIN',1,170752,3)
DBCC PAGE('ADMIN',1,170753,3)
DBCC PAGE('ADMIN',1,170754,3)
DBCC PAGE('ADMIN',1,170755,3)
LEVEL = 2 루트 페이지인 경우

LEVEL = 1 브랜치 페이지인 경우

LEVEL = 0 리프 페이지인 경우

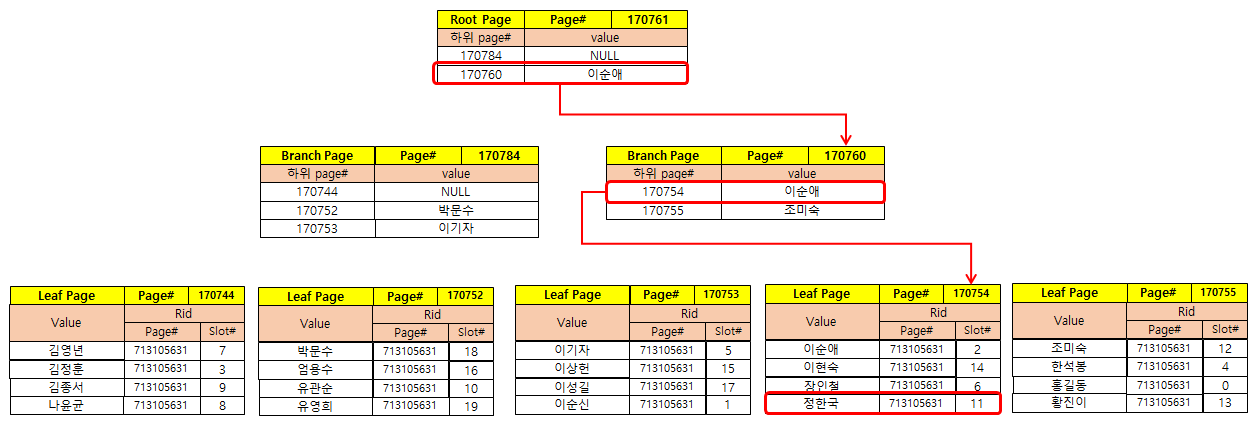
즉, 해당 인덱스를 B-TREE 로 도식화해보면 아래와 같이 표현할 수 있다.

리프페이지를 보면 인덱스 키 값뿐만 아니라 테이블 로우에 대한 RID 값도 저장되어 있다.
이 RID 값으로 '북마크 룩업' 오퍼레이션을 수행하여 나머지 칼럼 값을 가져온다.
리프 페이지는 앞뒤로 연결되어 있어서 순방향 또는 역방향 탐색이 가능하다.
리프 노드의 레벨은 0이며 위로 올라갈수록 레벨이 1만큼 증가한다.
리프노드를 제외한 루트, 브랜치 노드에 있는 페이지는 하위 노드에 있는
페이지를 가리키는 주소 정보와 인덱스 키 값을 갖고 있다.
SQL SERVER는 인덱스 키 값과 입력된 검색조건을 비교해
하위 노드에 있는 페이지 중 어디로 내려갈지 결정한다.
예를 들어서 name 이 '정한국'인 사람을 검색하면 아래와 같은 과정을 거치게 된다.
1) 루트노드인 170761번 페이지를 검색한다.
'정한국'이 현재 페이지의 두 번째 키 값인 '이순애' 보다 더 크기 때문에
두 번째 키가 가리키는 170760번 페이지로 내려간다.('ㅈ'가 'ㅇ' 보다 뒤에 나오기 때문)
2) 브랜치 노드에 있는 170460 페이지를 검색한다.
'정한국'이 현재 페이지의 첫 번째 값인 '이순애' 보단 크고 '조미숙' 보단 작으므로
첫번째 키가 가리키는 170754 페이지로 내려간다.
3) 리프노드에 있는 170754 페이지를 검색한다.
여기가 인덱스의 마지막 노드이므로 이 페이지에서 '정한국'과 정확히 일치하는 값을 찾는다.
713105631 페이지 11번 슬롯에 있는 RID 값을 얻는다.
이 페이지에 원하는 키 값이 없으면 테이블에 데이터가 없다는 뜻이므로
북마크 룩업(RID LOOK UP)을 수행하지 않는다.
4) 리프노드에서 얻은 RID 값으로 RID LOOK UP을 수행한다.
인덱스에 있는 RID 값을 해석하여 713105631 페이지
11번 슬롯을 찾아가서 나머지 칼럼 값을 읽어온다.
만약 필요한 정보가 인덱스 칼럼에 모두 포함되어 있다면 북마크 룩업을 수행하지 않는다.
아래와 같이 쿼리를 해주면 테이블 TBLINSATEST의 데이터가 존재하는 주소는 713105631이다.
그러므로 리프노드에서 Page# = 713105631가 된다.
SELECT * FROM sys.indexes WITH(NOLOCK) WHERE object_id = object_id('TBLINSATEST')
몇 번째 슬롯에 해당 데이터가 있는지 확인하기 위해서
아래와 같이 테이블 모든 칼럼을 쿼리 해준다.
SELECT * FROM dbo.TBLINSATEST WITH(NOLOCK)
정한국은 해당 테이블에 11번째 위치에 있기 때문에 Slot# = 11이 된다.
(Slot 은 0부터 시작하므로 11이 되는 것이다.)
정한국을 찾는 쿼리의 실행계획은 아래와 같다.
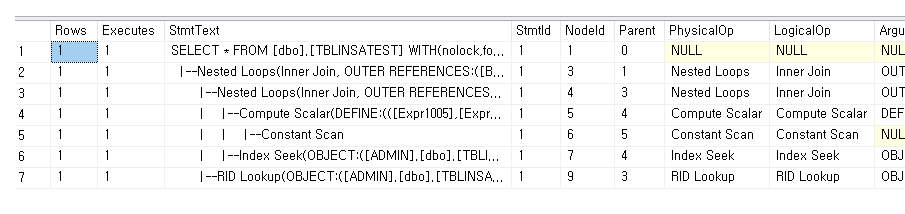


실행계획을 잘 보면 INDEX SEEK로 데이터를 찾아준 다음에 RID 룩업을 하고 있는데,
위의 테이블은 PK 가 없으므로 RID 룩업을 통해서
HEAP에 존재하는 테이블 데이터 페이지에 접근하여 테이블의 정보를 가져와주고 있다.
만약에, 해당 테이블에 PK 가 존재하였다면.
옵티마이저는 RID LOOKUP이 아닌 KEY LOOKUP을 통해
PK INDEX 페이지에 접근한 후에 데이터를 읽어올 것이다.
Index 탐색과 북마크 룩업
아래의 그림은 인덱스 탐색(INDEX SEEK)을 거쳐
힙 테이블을 북마크 룩업(RID LOOKUP, KEY LOOKUP) 하는 과정을 나타낸다.
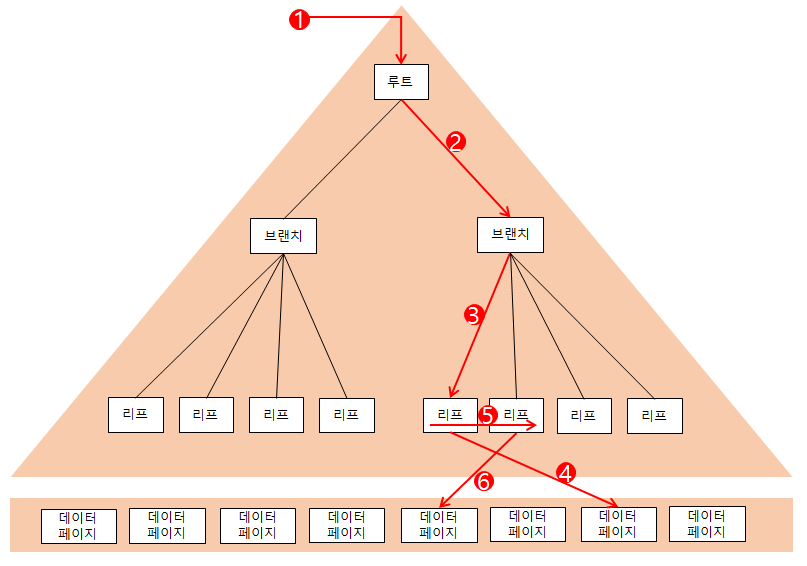
그림에서 각 화살표가 페이지 I/O 한 개라고 가정하면, 페이지 I/O가 총 6개 발생하였다.
1,2,3,5는 인덱스를 탐색하는 작업이고 4,6은 북마크 룩업(=테이블 액세스)하는 작업이다.
1,2,3과 4,6을 랜덤(RANDOM) 액세스라고 하는데,
한 건을 읽으려고 한 페이지씩 액세스 하는 방식을 말한다.
특히 RID 값으로 테이블 로우를 찾아가는 4,6의 랜덤 액세스가 SQL 성능에 큰 영향을 미친다.
1,2,3을 거쳐 5에서 얻은 RID 값이 100개라면 북마크 룩업,
즉 '테이블 랜덤 액세스'가 100회 발생하게 된다.
5는 시퀀셜(SEQUENCIAL) 액세스라고 하는데,
연속된 페이지를 순서대로 액세스 하는 방식을 말한다.
클러스터형 인덱스에서 넓은 범위를 탐색하거나 힙 테이블의 모든 로우를 검색할 때 유용하다.
시퀀셜 액세스는 랜덤 액세스보다 상대적으로 빠르지만,
5에서 불필요하게 넓은 범위를 액세스 하면 인덱스 탐색 효율에 문제가 발생하게 된다.
'SQL Tuning' 카테고리의 다른 글
| 인덱스 탐색 효율(SQL server) (0) | 2022.03.23 |
|---|---|
| 북마크 룩업 최소화 기법(3) - Covered Index (0) | 2022.01.29 |
| 북마크 룩업 최소화 기법(2) - Clustered Index (0) | 2022.01.28 |
| 북마크 룩업 최소화 기법(1) - 결합 인덱스 (0) | 2022.01.24 |
| [MSSQL] 인덱스란? (0) | 2021.12.20 |