
반응형
앞에서 스케줄러를 구성하는 컴포넌트에 대하여 알아보았다.
그러면 이제 클라이언트로부터 받은 쿼리를 처리할 때 스케줄러와 작업자가 어떻게 동작하는 지를
순서대로 확인해보자.
그러면 이제 클라이언트로부터 받은 쿼리를 처리할 때 스케줄러와 작업자가 어떻게 동작하는 지를
순서대로 확인해보자.
흐름의 포인트
-
CPU의 사용권을 다른 작업자에게 양보하고,
-
자신은 리소스를 획득할 때 까지 대기 상태가 된다는 것이다.
(1) 클라이언트가 SQL 서버에 접속하면 어느 하나의 스케줄러와 링크 된다.

(2-1) 클라이언트는 처리를 실행하기 위해 작업자가 필요하다.
(2-2) 작업자 스레드 풀에서 사용 가능한 작업자가 존재하는지 확인한다.
(2-3) 작업자가 있다면 클라이언트와 작업자를 바인드한다.

(3-1) 처리를 실행하기 위해서는 CPU 리소스를 할당 받아야 한다.
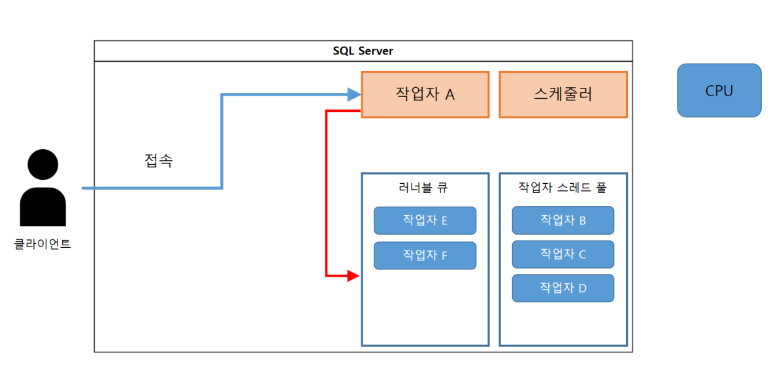
(3-2) 작업자 A는 러너블 큐에 추가된다.
(4-1) 러너블 큐의 상위에 있는 모든 작업자가 처리될 때 까지 대기한다.
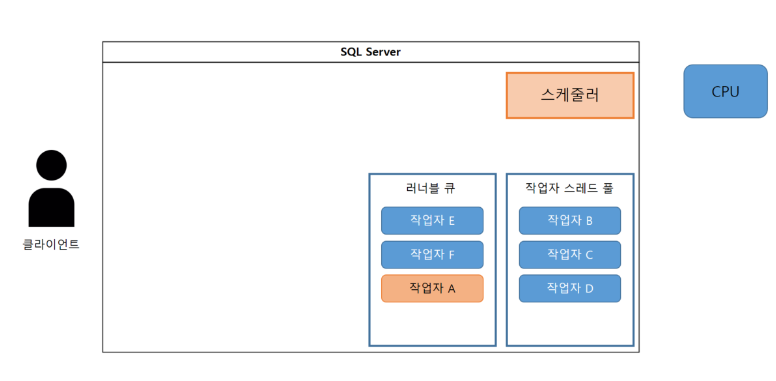
(4-2) 상위의 모든 작업자가 처리되고 작업자 A의 차례가 오면 작업자 A가 실행 상태로 올라간다.
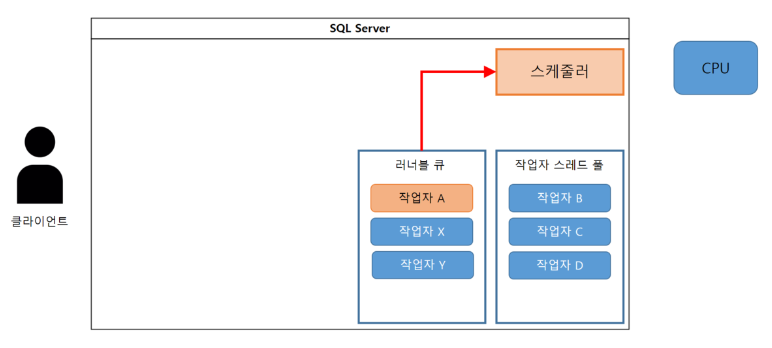
(4-3) CPU 리소스에 할당되어 처리가 실행되고, 실행 중이라는 정보가 스케줄러에 보관된다.
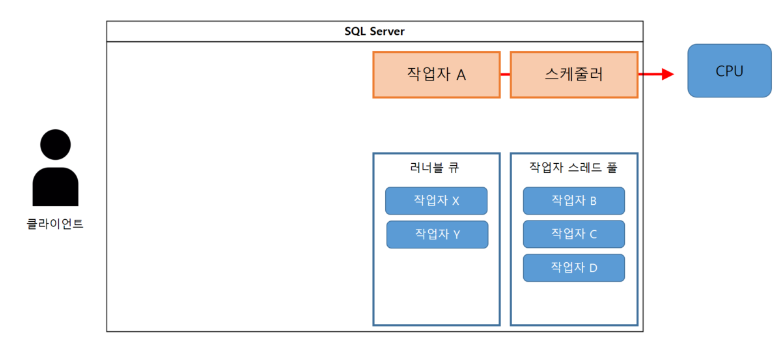
(5-1) 작업자 A가 처리를 진행하면 테이블 X 전체에 배타 락이 필요해진다.
(5-2) 그러나 이미 다른 작업자가 테이블 X에 대한 락을 획득하고 있다.
(5-3) 따라서 작업자 A는 테이블 X에 대한 웨이터 리스트에 추가된다.
(5-4) 또 스케줄러의 사용권을 러너블 큐의 선두 작업자에게 넘기고 자신은 대기 상태가 된다.

(6) 일정 시간 경과 후 테이블 X의 배타 락을 획득한 작업자 A는 다시 러너블 큐에 추가 된다.

(7) 상위에 있던 작업자의 처리가 완료가 될 때까지 대기 한 후, 작업자 A는 다시 실행 상태가 된다.

(8-1) 다음에 작업자 A는 데이터 취득을 위해 디스크에 대한 I/O가 필요하다.
(8-2) 때문에 I/O 리퀘스트를 수행한다.
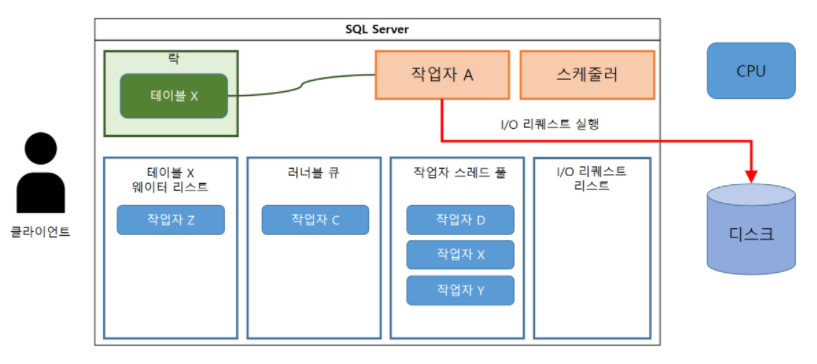
(9-1) 작업자 A는 I/O 리퀘스트 리스트에 등록된다.
(9-2) 그리고 스케줄러 사용권을 러너블 큐의 선두 작업자에게 넘긴다.
(9-3) 자신은대기 상태가 된다.

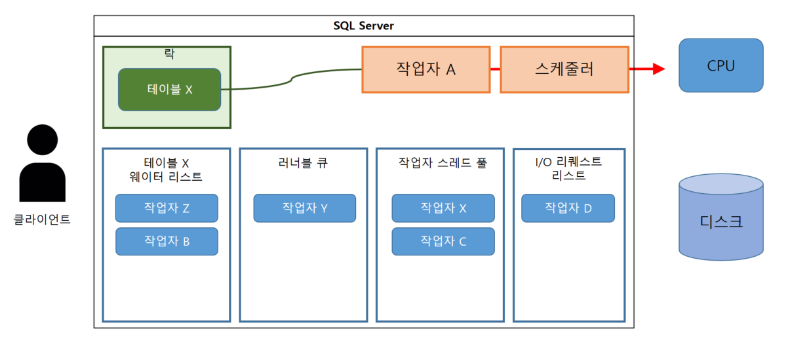
(10-1) 일정 시간 경과 후, I/O 리퀘스트가 완료된다.
(10-2) 작업자 A는 처리를 계속하기 위해 러너블 큐로 이동한다.

(11-1) 러너블 큐에서 대기 시간이 지난 후 작업자 A는 실행 상태가 된다.
(11-2) 필요한 처리를 계속한다.
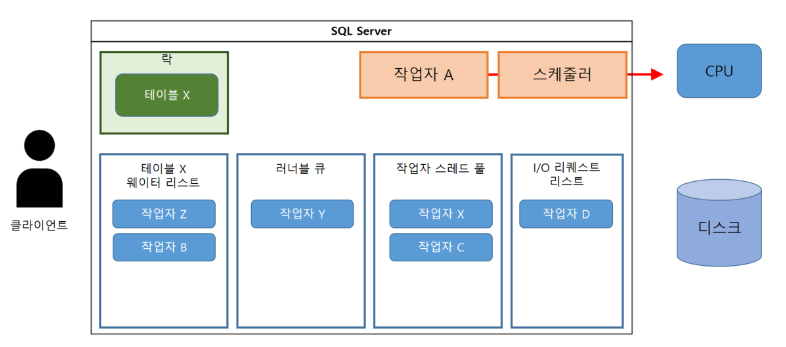
(12-1) 작업자 A는 획득한 테이블 X의 락을 해제한다.
(12-2) 웨이터 리스트의 선두 작업자에 획득권을 건넨다.
(13) 작업자 A는 처리 결과를 클라이언트에 회신한다.
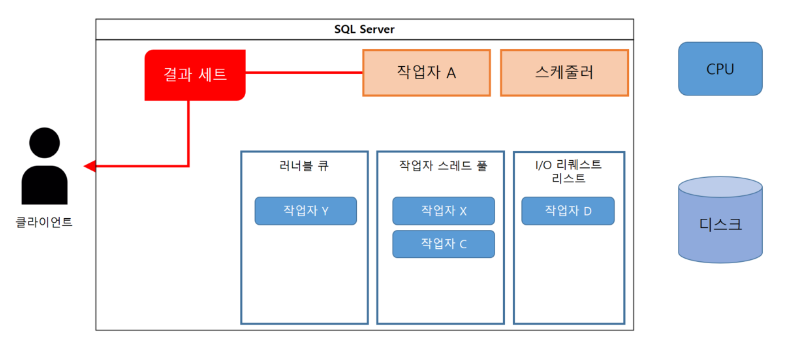
(14) 모든 작업을 마친 작업자 A는 스레드 풀에 자신을 등록한다.

(15) 다음에 사용될 때 까지 대기 상태에 들어간다.
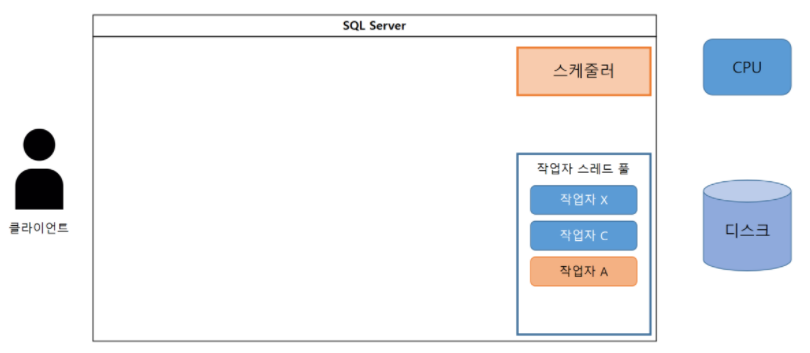
작업자, 스케줄러 동작 흐름의 개요는 간략하게 이러한 내용이다.
실제로는 더 많은 횟수의 리소스 대기 상태와 실행 상태 사이를 오간다.
반응형
'DB ARCHITECTURE' 카테고리의 다른 글
| [MSSQL] LOCK (0) | 2021.12.16 |
|---|---|
| 트랜잭션의 정의 및 동작 원리 (0) | 2021.12.16 |
| SQL-SERVER SCHEDULER : sqlserver 스케쥴러(1) (0) | 2021.12.15 |
| SQL-SERVER SCHEDULER : 윈도우 스케쥴러 (0) | 2021.12.15 |
| 정규화(Normalization) (0) | 2021.08.02 |