
현재 회사에서 Elasticsearch를 운영하고 있다.
Elasticsearch는 매일 monitoring-es ~라는 인덱스를 자동으로 인덱싱 한다.
해당 인덱스는 X-Pack 모니터링 기능이 활성화되어 있을 때 자동으로 생성되며,
클러스터의 성능, 상태 및 메트릭에 대한 상세 정보를 포함한다.
보통 monitoring-es 인덱스는 아래와 같은 정보를 저장해 준다.
1) 클러스터 상태 정보
클러스터의 건강 상태, 노드 수, 인덱스 수, 샤드 수 등 클러스터 전반에 대한 상태 정보.
2) 노드 메트릭
각 노드의 CPU 사용량, 메모리 사용량, 디스크 I/O 통계, JVM 통계(가비지 컬렉션, 힙 메모리 사용량 등),
네트워크 사용량 등 노드별 성능지표.
3) 인덱스 메트릭
각 인덱스의 샤드 할당 상태, 문서 수, 저장 공간 사용량, 인덱싱 및 검색 작업에 대한 성능 지표.
4) 샤드 메트릭
각 샤드의 상태, 문서 수, 저장 공간 사용량 등 샤드별 상세 정보.
5) 시스템 메트릭
운영 시스템에 대한 정보, 시스템 부하, 프로세스가 실행 중인 시간 등입니다.
6) Elasticsearch 로그 및 오류
클러스터, 노드, 인덱스에 관한 로그 메시지와 오류 메시지.
현재 회사에서는 운영 중인 elasticsearch cluster에서. monitoring~ 인덱스를 수집하여
특정 metric에 문제가 생길 경우 (예를 들어 disk 사용률이 임계치 이상으로 올라갈 때)
Telegram Bot을 통하여 알람을 보내주고 있다.
그런데 오늘 아침 출근할 때 아래와 같은 에러가 계속 울리는 것이 아니겠는가?
처음에는 단순히 탐지오류이거나, 인덱스 생성시점에 체크를 한 것이라
인덱스가 없다고 알람이 온 줄 알았다.

하지만, 위의 에러는 계속 지속되었고, 원인을 파악해 보기로 했다.
Kibana Dev Tool로 아래와 같은 명령어를 쿼리 했다.
GET /.monitoring-es-7-2023.12.27/_search
하지만, 아래와 같은 에러메시지만 리턴될 뿐이었다.
{
"error" : {
"root_cause" : [
{
"type" : "index_not_found_exception",
"reason" : "no such index [.monitoring-es-7-2023.12.27]",
"resource.type" : "index_or_alias",
"resource.id" : ".monitoring-es-7-2023.12.27",
"index_uuid" : "_na_",
"index" : ".monitoring-es-7-2023.12.287"
}
],
"type" : "index_not_found_exception",
"reason" : "no such index [.monitoring-es-7-2023.12.27]",
"resource.type" : "index_or_alias",
"resource.id" : ".monitoring-es-7-2023.12.27",
"index_uuid" : "_na_",
"index" : ".monitoring-es-7-2023.12.27"
},
"status" : 404
}
운영하고 있는 Elasticsearch cluster는 utc 기준으로 인덱싱 되고 있으며,
한국시간 기준으로 오전 9시에 새로운 monitoring 인덱스가 인덱싱 되는 게 맞는데
monitoring 인덱스가 생성되지 않고 있던 것이다.
더 자세한 원인 파악을 위해서
해당 서버에 직접 접근하여 로그를 살펴보기로 했다.

원인은 maximum normal shard open 에러였다.
해당 에러는 데이터 노드에서 사용할 수 있는 샤드가 최대치에 도달해서
더 이상 샤드를 할당할 수 없고, 그로 인해 새로운 인덱스를 인덱싱 하지 못하여 발생하는 오류이다.
해당 문제가 발생한 elasticsearch cluster 구조는 아래와 같다.

현재 해당 클러스터는 master/ingest 역할을 하는 노드 3개와
데이터 노드 3개로 구성되어 있다.
로그파일에 써져 있는 오류중에 유심히 봐야 할 것은
"cluster currently has [3000]/[3000]" 해당 부분이다.
Elasticsearch에서 샤드는 데이터를 저장하고 검색 쿼리를 처리하는 역할을 하는 데이터 노드에만 할당된다.
각 노드당 최대의 샤드개수를 뜻하는 시스템 필드인 "cluster.max_shards_per_node"는
기본적으로 1000의 값을 갖는다.
즉, 3개의 데이터 노드가 있으므로, 할당가능한 샤드의 최대치는 3000인데,
새로운 인덱스를 구성하려고 샤딩을 해주려다 보니 더 이상 할당 가능한 샤드가 없어서 문제가 생긴 것이다.
이 문제를 해결하기 위해서 kibana dev로 접근하여 아래와 같은 명령어를 쿼리 했다.
PUT /_cluster/settings
{
"persistent": {
"cluster.max_shards_per_node": 4000
}
}
위의 쿼리는 각 노드의 허용가능한 최대샤드를 1000 -> 4000으로 늘려주는 것이다.
즉 데이터 노드가 3개 이므로 총 할당가능한 샤드는 12,000 개가 된다.
해당 옵션이 작 적용되었는지 확인하려면 아래와 같은 명령어를 쿼리 할 수 있다.
GET /_cluster/settings

그럼 샤드가 다시 재 할당되어 인덱스가 생성되고 있는지 확인해 보자.
kibana에서도 확인 가능하지만 서버에 직접 접근해서 총샤드의 개수를 뽑아보겠다.
curl -s -XGET "http://{아이디}:{비밀번호}@{아이피주소}:{포트번호}/_cat/shards" | wc -l
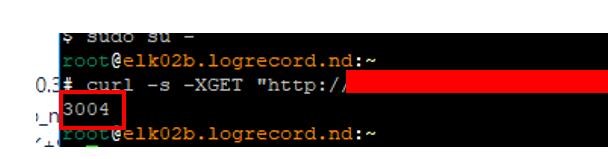
정상적으로 4개의 샤드가 더 할당된 모습을 볼 수 있다.
'Elasticsearch' 카테고리의 다른 글
| [Elasticsearch] GC Log 분석 (0) | 2024.12.26 |
|---|---|
| [Elasticsearch] 검색성능 비교 (0) | 2023.05.15 |
| [Elasticsearch] Nori 분석기 적용 (0) | 2023.05.14 |
| [Elasticsearch] Disk-based shard allocation (1) | 2023.03.02 |
| [Elasticsearch] text, keyword 타입 (0) | 2023.03.02 |